字节跳动开源大模型训练框架veGiantModel
3月17日消息,据IT之家消息,近日,字节跳动应用机器学习团队开源了一款名为veGiantModel的大模型训练框架,主要应用于自然语言处理领域的大模型训练,最高可将大模型训练的性能提升6.9倍,大幅降低训练系统的压力。
目前,字节跳动旗下的企业级技术服务平台火山引擎已在其机器学习平台上原生支持了该框架,该平台正在公测中。

据了解,自然语言处理是人工智能研究的一个重要领域,旨在帮助计算机理解、解释和运用人类语言,可应用于机器翻译、个性化推荐和信息提取等领域。
近些年,自然语言处理在应用方面取得了较为显著的突破,主要归功于深度学习以及相关技术的发展,尤其是Bert、GPT、GPT-3等大规模预训练语言模型的普及。
针对现有训练系统在大模型训练场景下的显存压力、计算压力和通信压力挑战,字节跳动应用机器学习团队提出了大模型训练框架veGiantModel。大规模训练模型可以包含更多数据,表示更多信息,算法表现更加出众。
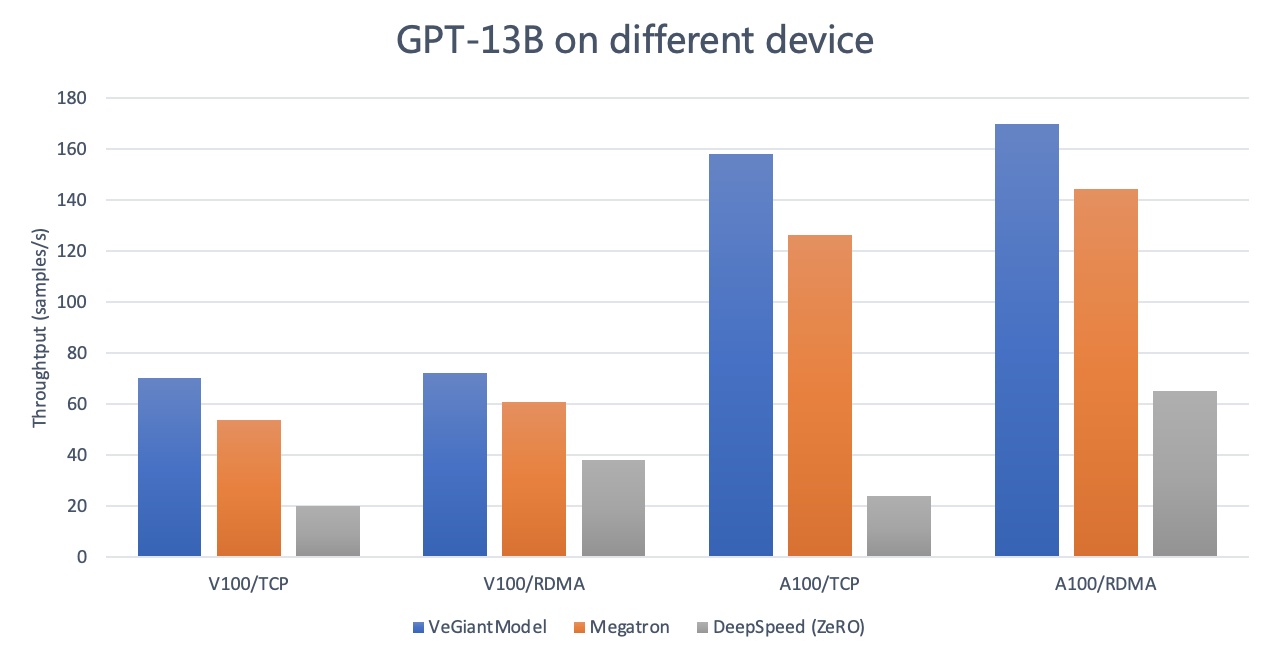
与主流开源训练框架的对比测试显示,veGiantModel的性能表现最好、受网络带宽影响最小,在Tesla V100上较Megatron、DeepSpeed有1.2倍到3.5倍的提升,在Ampere A100上最高可提升6.9倍。
据报道,近年来,字节跳动持续推动技术开源。2021年,字节跳动技术团队陆续开源了微服务中间件CloudWeGo、LightSeq训练加速引擎等30余个重要项目。
字节跳动相关技术负责人表示,推广科技创新成果的应用并推行技术开源一直是公司所倡导的,技术团队将持续通过科技创新为行业发展提供更多动力,助力科技更好地造福社会。
声明:
- 该内容为作者独立观点,不代表电商报观点或立场,文章为作者本人上传,版权归原作者所有,未经允许不得转载。
- 电商号平台仅提供信息存储服务,如发现文章、图片等侵权行为,侵权责任由作者本人承担。
- 如对本稿件有异议或投诉,请联系:info@dsb.cn





