小米突然放大招,开源大模型干趴阿里、Open AI
好戏才刚刚开始。
一、小米首个大模型开源
大模型领域,也被小米搅动得天翻地覆。
近日,小米宣布,其首个推理大模型Xiaomi MiMo开源。
值得注意的是,其中经强化学习训练形成的MiMo-7B-RL模型,在数学推理(AIME 24-25)和代码竞赛(LiveCodeBench v5)公开测评集上,仅用7B参数量,得分不仅超过了OpenAI的闭源推理模型o1-mini,还打败了对手阿里Qwen开源推理模型QwQ-32B-Preview。
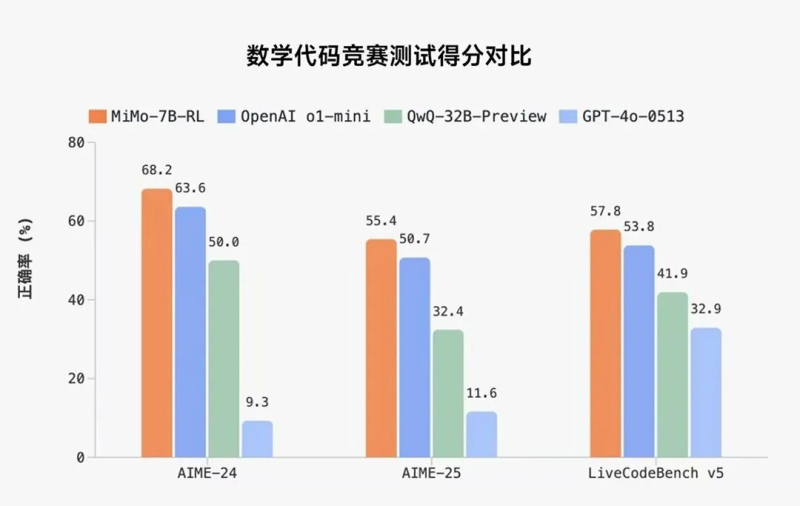
图源:微博
在相同强化学习训练数据情况下,MiMo-7B-RL在数学和代码推理任务上均表现出色,分数超过DeepSeek-R1-Distill-7B和Qwen2.5-32B。
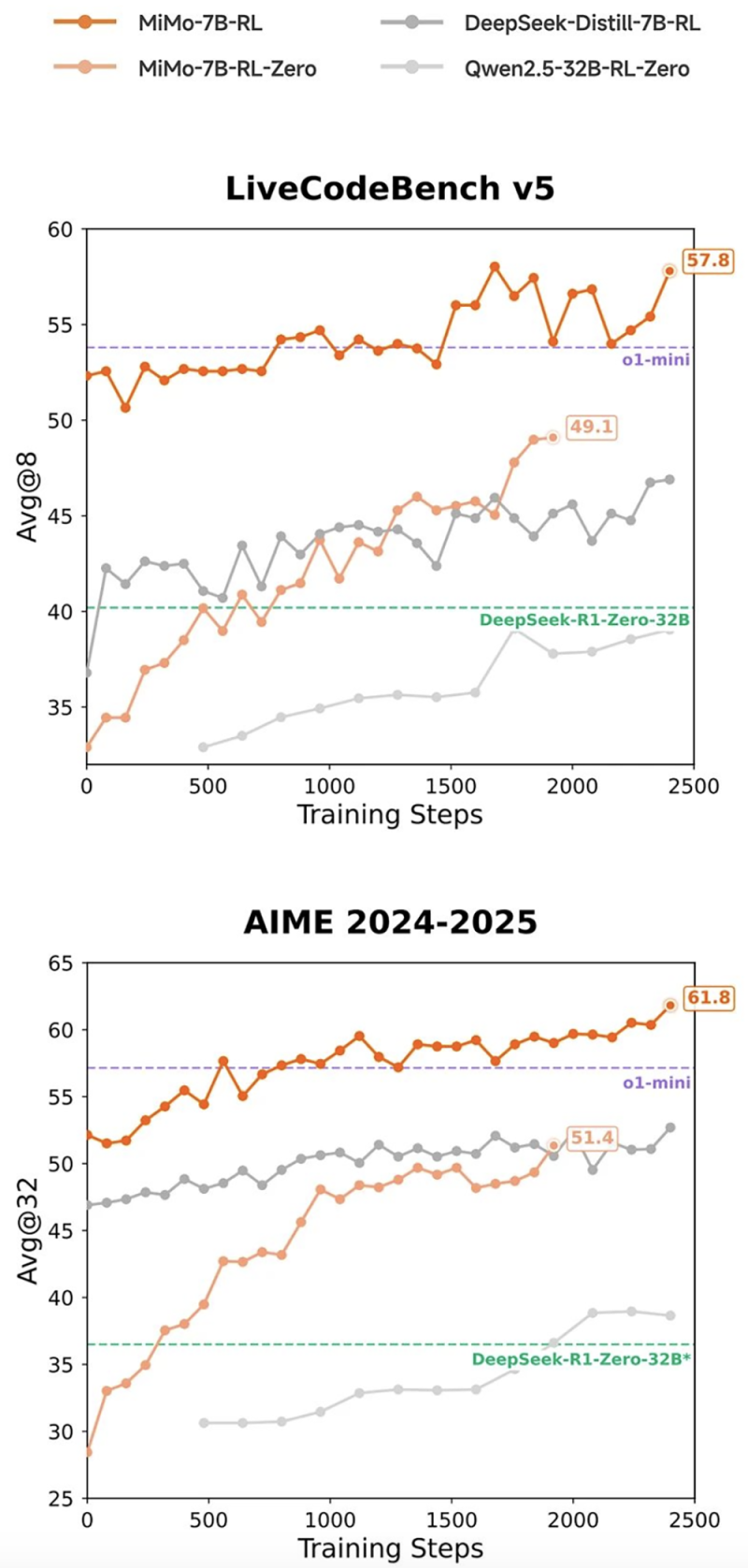
图源:微博
图源:微博
目前,MiMo-7B 已在 Hugging Face 平台开源 4 个模型版本,分别是:
·MiMo-7B-Base:预训练模型
·MiMo-7B-SFT:监督微调模型
·MiMo-7B-Base-Zero:基于MiMo-7B-Base直接强化学习的模型
·MiMo-7B-RL:基于MiMo-7B-SFT强化学习的模型

图源:微博
同时,技术报告也同步上线 GitHub,向开发者与研究者全面开放。

图源:微博
预训练阶段,模型整体数据量为25T Tokens,核心是让模型见过更多推理模式。预训练分为渐进式三阶段:
第一阶段以常识性推理为主,主要如涉及数学应用题、基础代码片段;
第二阶段引入多步骤逻辑链条,如组合数学问题、动态规划算法,为了不影响模型通用能力,混入部分通用数据,比例为7:3。
第三阶段要为了提高模型解决复杂任务的能力,聚焦于国际竞赛级难题,比如AIME 2024-2025中的奥赛题目,和创造性写作数据,并将上下文长度从8192扩展到32768。

图源:微博
“分阶爬坡”的策略有效避免了模型在早期陷入局部最优解,同时通过逐步提升思维负荷强化神经网络的泛化能力。
后训练阶段,MiMo实现“小参数越级挑战”的关键。团队构建高质量强化学习(RL)数据集,包含13万道经过严格清洗与难度标注的数学题和编程题。每道题目均配备基于规则的验证器,确保奖励信号的客观性与可复现性,从而规避了传统RLHF(人类反馈强化学习)中主观偏好导致的模型偏差。
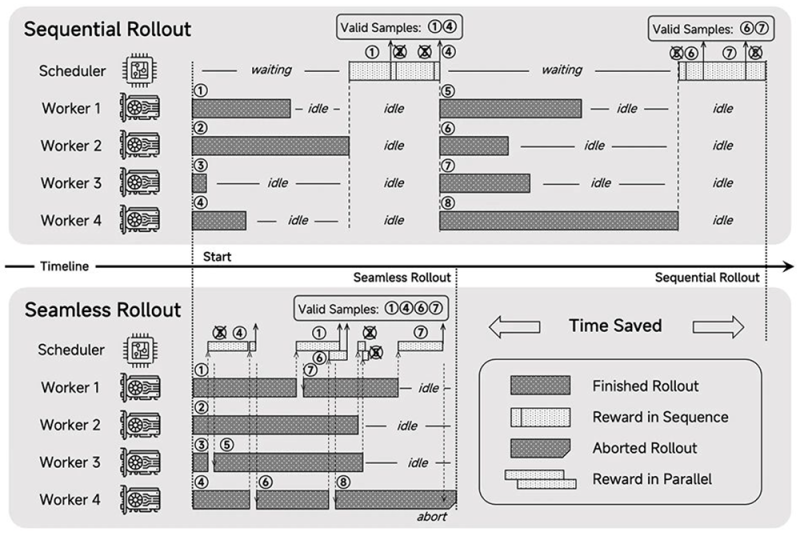
图源:微博
框架层面的突破则体现在Seamless Rollout系统的设计上。该系统将策略部署、异步奖励计算与提前终止功能集成于统一架构,通过动态调度GPU资源,将强化学习训练速度提升2.29倍,验证效率加快1.96倍。
那么,我们来聊一聊,小米这种开放姿态,对于其本身战略定位和大模型行业来说,有什么意义。
一方面,将MiMo与早前开源的Vela物联网系统、米家智能家居协议深度绑定,小米企图构建的“模型-硬件-场景”三位一体的开放生态便会越来越清晰。
比如,基于MiMo开发的语音助手,开发者可直接接入小米智能家居设备。或者,借助车载推理引擎,无缝对接小米汽车OS系统。
作为一家产品销量可观的智能设备公司,小米开放了核心AI模型,意味着,或许不久的将来,更多的智能终端将被纳入其技术轨道。对于友商来说,压力确实不小。
另一方面,仅仅其以7B的参数规模,就超越了阿里32B模型和OpenAI闭源产品的成绩,可以说,直接颠覆了行业对“参数规模决定性能”的固有认知。
并且,此次开源,开发者无需支付高昂API费用即可调用模型,使用门槛大大降低。当然,用户规模的扩大,意味着更多的使用数据,反过来也会进一步反哺小米大模型的开发。
当然,股票市场对于小米这次动作的反应也十分乐观和迅速。截至午间休市,小米集团今日股价直接上涨4.74%,总市值1.29万亿港元(约合人民币1.21万亿元)。
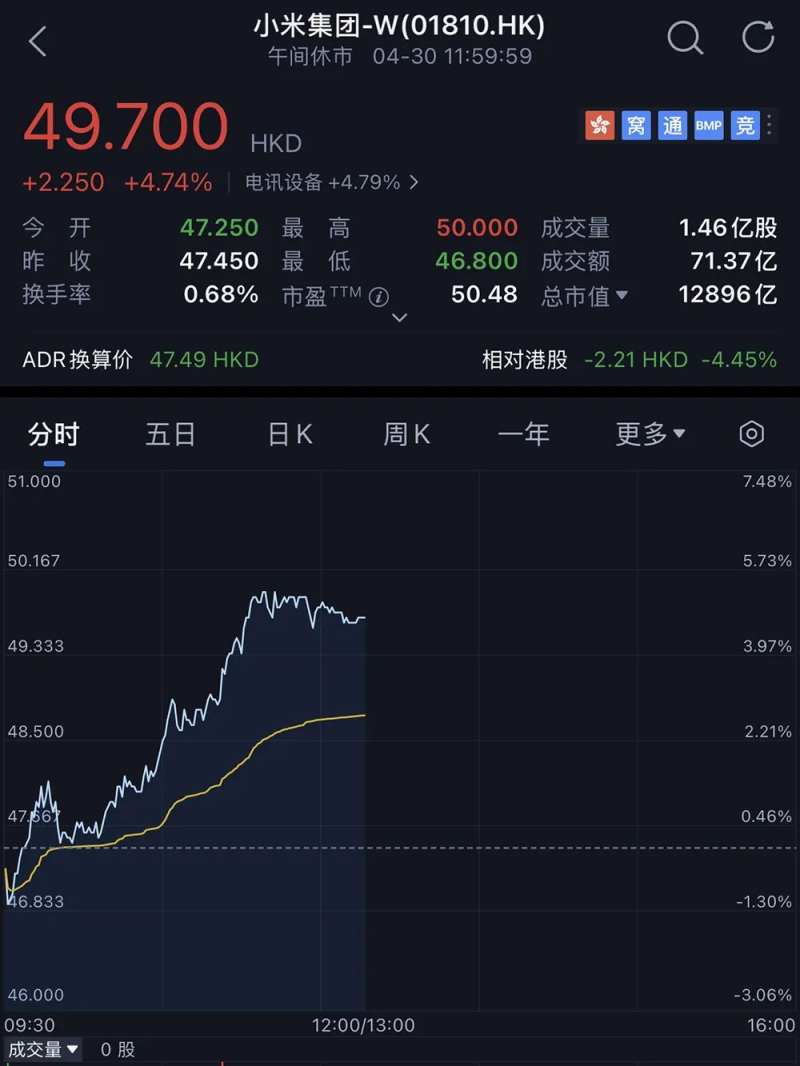
图源:小红书
值得注意的是,此次开源的MiMo,是来自全新成立不久的“小米大模型 Core 团队”的初步尝试。
此前,曾有报道称小米创始人雷军以千万年薪挖角 AI 天才少女罗福莉,后者曾在 DeepSeek 任职研究员,并参与 DeepSeek-V2 等大模型研发工作。
如今交出这样一份答卷,可以说,让公众对小米大模型的未来,不禁有了更多想象的空间。
二、小米一向是个“逆袭者”
从手机、到家电、再到汽车,小米拿到入场券的时间都不算早,但这个企业,总能依靠独特的打法实现后来居上。
比如,2011年,雷军带着小米手机杀入市场时,苹果、三星已封神多年,也许没人相信小米能搅动风云。

图源:抖音
但就在三年后的2014年,小米通过极致性价比和技术堆料策略,一举登顶中国市场份额第一。
而就在前两天,小米手机再次以出货量1330万台,市场份额18.6%的成绩,登顶中国区销量榜。
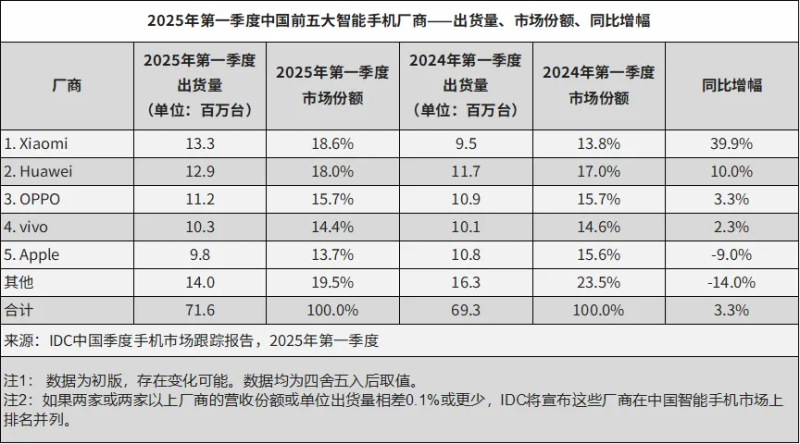
图源:微博
为此,沉默多天的雷军也现身发文庆祝。
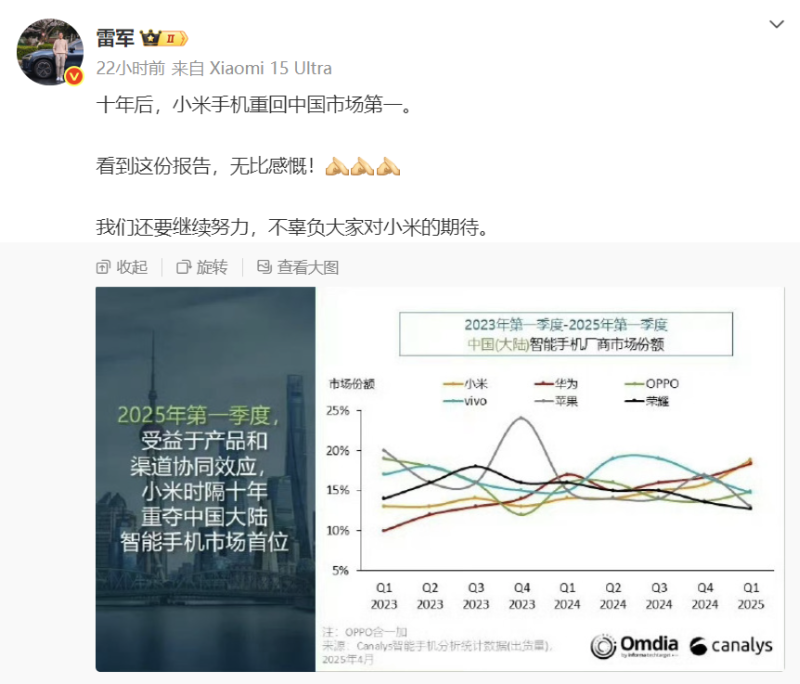
图源:微博截图
再比如,2021年,小米宣布造车,此时“蔚小理”的名声已经在国内市场打响。但很显然小米造车的销量再次出乎意料。
2024年,小米SU7上市24小时内大定订单突破8.8万台,全年交付量达13.6万辆,远超原定目标。

图源:微博
最后,到如今的小米大模型,其实,与不少友商互联网大厂相比,小米进军的时间并不长。
2023年4月,雷军亲自宣布,小米将成立大模型团队,并且,雷军明确提出“不搞军备竞赛”,专注轻量化与端侧部署。
同年8月,小米首次发布了自研大模型MiLM-6B(64亿参数),并在中文评测榜单C-EVAL和CMMLU中,一举夺得同参数量级第一的成绩。
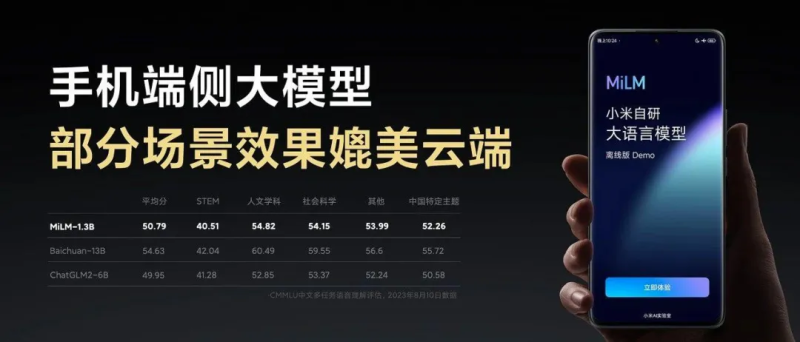
图源:微博
该模型采用“大数据+大任务+大参数”的范式,通过自研的ScaledAdam优化器和Eden学习率调度器提升训练效率,同时依托小米生态80%的自有数据(包括3TB产品业务数据)进行深度优化。
第二年5月,MiLM正式通过澎湃OS系统和小爱同学实现了消费端的落地应用。小米手机端的AI图片编辑、平板端的自动生成会议纪要、电视端的影视问答等,都有它的协同参与。
小米第二代模型MiLM2,是在2024年11月发布的,此次迭代不仅扩充了训练数据的规模,也在训练策略与微调机制上进行了打磨。

图源:微博
这次更新的成绩也很吸睛,参数范围扩展至0.3B-30B,推理速度提升了34%,量化损失降低了78%。
可以说,大模型的发展历程,实质是小米在AI 2.0时代对“规模扩张”与“价值创造”的重新平衡,通过将开源生态、云边协同与通用能力三大要素深度融合,重新书写中国科技企业参与全球AI竞赛的新叙事。
三、小米的前路并不轻松
当然,在这场小米大模型的开源狂欢过后,小米的前路也许并不轻松。
一方面,从技术角度来看,小米模型目前仅支持文本输入,与强劲的对手OpenAI相比,在多模态能力和应用场景拓展上还存在一定差距。
与此同时,当前7B模型虽然适配端侧芯片,但随着多模态能力的扩展,未来小米可能面对在模型复杂度与硬件兼容性间权衡的难题。
不过,小米技术团队似乎已经意识到这一点。据其开源技术报告披露,下一代MiMo模型将引入动态多模态融合模块,通过跨模态注意力机制整合文本、图像甚至传感器数据。
另一方面,外部竞争对手正在逐步加快开发的进程,火药味越来越浓。友商科技头部企业,如阿里巴巴、腾讯、华为、字节跳动等,你追我赶。
图源:微博
例如,就在前两天,百度在Create2025AI开发者大会上,也发布了两款开源大模型:文心大模型4.5 Turbo及深度思考模型X1 Turbo。百度大模型的实力也确实“不一般”。

图源:微博
甚至,2025年来,全球基础模型数量已经突破了500个,纯文本模型的性能差距逐渐收窄。因此,留给小米的压力不小。
但无论如何,MiMo的开源已为中国AI发展提供新范式,至少,它证明技术突破未必需要千亿参数的军备竞赛,并且,生态共赢远比闭源垄断更具生命力。
在大模型领域,小米究竟能掀起怎样的浪潮,或许时间会给出答案,让我们拭目以待。
2、电商号平台仅提供信息存储服务,如发现文章、图片等侵权行为,侵权责任由作者本人承担。
3、如对本稿件有异议或投诉,请联系:info@dsb.cn


