DeepSeek重磅升级,影响太大,冲上热搜
沉默了两个月,DeepSeek出手就是王炸。
在端午节来临前夕,DeepSeek悄悄完成了一次小版本升级,当前版本为DeepSeek-R1-0528。
迄今为止,DeepSeek最震动世界的动作还是1月发布R1。而之后DeepSeek的热度就开始下降,使用率也有所回落,并且引发了一些质疑。
今年3月,DeepSeek放出了 DeepSeek-V3-0324 模型。时隔两月,DeepSeek再次进行模型更新。
我们不禁好奇,这次更新又会给我们带来怎样的惊喜?

图源:微博
一、四大实用升级,普通人也用得到
根据DeepSeek官方公告,DeepSeek-R1-0528使用2024年12月所发布的DeepSeek V3 Base模型作为基座,但在后训练过程中投入了更多算力,显著提升模型的思维深度与推理能力。
这次更新,DeepSeek主要升级了几个十分实用的功能。
第一,DeepSeek的思考能力深化。
根据官方介绍,更新后的 R1 模型在数学、编程与通用逻辑等多个基准测评中取得了当前国内所有模型中首屈一指的优异成绩,并且在整体表现上已接近其他国际顶尖模型,如 o3 与 Gemini-2.5-Pro。
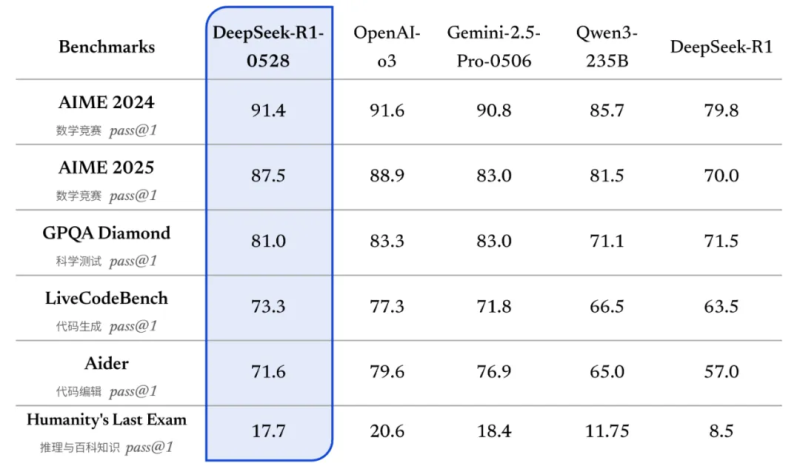
图源:DeepSeek官网
最左边那栏是测试集,可以看到DeepSeek-R1-0528 在各项评测集上均取得了优异表现。
并且,相较于旧版 R1,新版模型在复杂推理任务中的表现有了显著提升。例如在 AIME 2025 测试中,新版模型准确率由旧版的 70% 提升至 87.5%。
举个例子,DeepSeek-R1-0528现在也能做对数字新难题“9.9-9.11=?”了。

图源:DeepSeek
要知道,这种看似简单的数学题能难倒o3、Gemini 2.5 pro、Claude 4等一众顶流大模型。
另外,这次更新中,上下文长度扩展至164K tokens,支持单任务最长60分钟的深度思考,这意味着处理复杂任务的能力提升了。
DeepSeek表示,DeepSeek-R1-0528的思维链对于学术界推理模型的研究和工业界针对小模型的开发都将具有重要意义。
第二,新版 DeepSeek R1 针对“幻觉”问题进行了优化。
“AI幻觉”(AI Hallucination)这一现象,表现为模型输出与输入无关、违背事实或逻辑的内容,例如虚构事实、编造引用、错误数据等。
在一定测试样本中,AI输出包含幻觉内容的比例就是幻觉率。
相信不少人在网上都看过这样的吐槽:本来想要借助DeepSeek写文章,结果发现它给出的参考文献根本不存在!
这就是AI幻觉。
AI幻觉常见表现就是捏造不存在的研究论文或作者,或是提供错误的历史事件、日期或科学结论,以及生成与上下文无关的矛盾回答。
原因有三方面:训练数据噪声或偏差;模型过度依赖统计模式而非真实理解;提示模糊或引导不当。
总而言之,幻觉率是评估AI可靠性的重要指标。
而旧版相比,更新后的模型在改写润色、总结摘要、阅读理解等场景中,幻觉率降低了 45~50% 左右,能够有效地提供更为准确、可靠的结果。
不得不说,这是很实用的一大进步。
第三,新版 DeepSeek R1在创意写作、代码生角色扮演等功能上有了很大的优化。
旧版 R1 的基础上,更新后的 R1 模型针对议论文、小说、散文等文体进行了进一步优化,能够输出篇幅更长、结构内容更完整的长篇作品,同时呈现出更加贴近人类偏好的写作风格。

图源:DeepSeek官网
而在编程测评中,R1-0528与OpenAI的o3-high版本表现接近,部分任务甚至超越Claude 4 Sonnet等顶尖模型。
例如,生成带有动画效果的天气卡片代码时,R1的设计细节和交互动画完成度优于Claude。
图源:微博
图源:微博
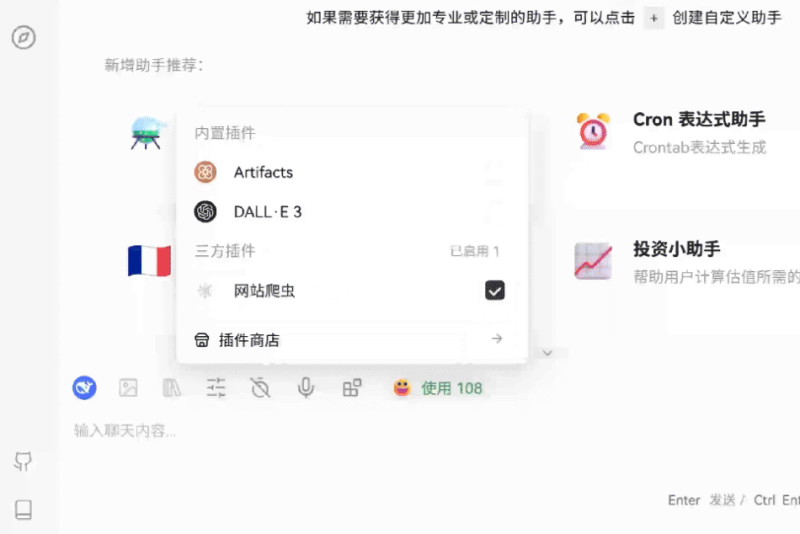
第四,DeepSeek-R1-0528 支持工具调用(不支持在 thinking 中进行工具调用)。
根据官方介绍,当前模型 Tau-Bench 测评成绩为 airline 53.5% / retail 63.9%,与 OpenAI o1-high 相当,但与 o3-High 以及 Claude 4 Sonnet 仍有差距。
图源:DeepSeek官网
总结一下,根据中国经济网报道,升级主要有四个方面。
首先,响应质量优化。
对复杂推理、多步骤计算更准确;长文理解与生成更连贯、逻辑更清晰;数学、编程等专业性输出更可靠。
其次,响应速度小幅提升。
在网页端、App、API 接口中响应更敏捷,尤其在处理超长文本输入时,延迟有所降低(约提升 10%~20%)。
再次,对话稳定性增强。
上下文记忆更稳定,尤其在超长对话中,并且减少偶尔“遗忘设定”或“跑偏”的情况。
最后,API 和接口兼容性保持稳定。
如公告所说:API 调用方式、参数、返回结构完全不变,用户无需调整现有集成,即可无缝使用新版本。
换句话说,日常生活中,现在的DeepSeek-R1-0528 已经足够应对大多数问题,而在学习和工作中,DeepSeek-R1-0528的可靠性大大提升、使用体验也变好了。
二、强如DeepSeek,叫板国外AI大模型
在现在这个人人都在卷AI的时候,DeepSeek还保留着独特的优势。
首先,在开源策略上,更新后的DeepSeek-R1依然选择开源。
DeepSeek采用MIT协议开源,允许免费商用,甚至不用公开自己的修改代码,极大降低了AI应用门槛。
其次,DeepSeek成本优势显著,开发者狂喜。
其API价格仅为OpenAI o1的1/50(输入token)至1/27(输出token),也就是同样处理字数的文本,用R1需要的成本比用OpenAI低很多,
因此,在性价比方面,DeepSeek称第二,没人敢称第一。
最后,DeepSeek与国内应用市场的适配度很高。
目前DeepSeek已经接入许多应用,例如华为小艺、腾讯元宝等,有着广泛的用户基础。
并且国产硬件,如华为昇腾910B芯片已完成适配,支持本地化部署,彻底摆脱对英伟达的依赖。
然而,DeepSeek还有许多可以优化的空间。

图源:微博
一方面,测评显示,R1在编程能力上与o3-high接近,数学推理优于Gemini 2.5 Pro,但工具调用能力仍存在差距。
另一方面,暂不支持图片、语音等多模态输入,在日常使用中有局限性。
另外,在创意写作、多轮对话等场景,R1和顶级模型仍有差距。尽管幻觉率降低,模型在长文本对话中仍可能出现逻辑错误,并且部分用户反馈服务响应存在延迟,“服务器繁忙,请稍后重试”恐怕也是人们对DeepSeek的重要印象之一。
图源:微博
三、万众期待的R2何时到来
迄今为止,DeepSeek最震动世界的动作还是1月发布R1。
今年3月,DeepSeek放出了 DeepSeek-V3-0324 模型,主要优化了代码方面的功能。该模型全面超越 Claude-3.7-Sonnet,在数学、代码类相关评测集上超过 GPT-4.5。
而当前,市场最关心的依然是R2模型发布。
4月初,DeepSeek联手清华大学发布一篇论文,提出一种名为自我原则点评调优(SPCT)的新学习方。同时,研究者引入了元奖励模型(meta RM),进一步提升推理扩展性能。
上述论文引发了DeepSeek的R2是否很快面世的猜测。
而这次版本升级,再次激起了人们对R2的期待。
有人认为,这次的小版本升级可能意味着,R2还远未准备好推出。
也有人认为,这次优化这么多功能都只是一次“小版本升级”,那么R2如果出来,其影响力想必不会输给R1。
图源:微博
DeepSeek-R1的升级像一场静水深流的变革——它没有渲染“颠覆世界”的野心,却用更长的思考时间、更低的犯错率、更贴近普通人的成本,悄悄改写了“强者恒强”的AI叙事。
这一次,我们看到的不是参数竞赛的喧嚣,也不是资本游戏的狂欢,而是一个朴素的真相:真正的进步,往往藏在“够用就好”的克制里。
技术的光芒,本就该照进这些具体而微的生活褶皱里。
2、电商号平台仅提供信息存储服务,如发现文章、图片等侵权行为,侵权责任由作者本人承担。
3、如对本稿件有异议或投诉,请联系:info@dsb.cn



